近日,AMD和英伟达接到消息,美国政府要求其对中国区断供高端GPU。8月31日晚,集微网突然发布消息称,AMD和英伟达中国区已相继接到总部通知,要对中国区客户断供用于人工智能和数据中心的顶级计算芯片。 AMD方面:
英伟达方面:
目前,英伟达H100在今年GTC大会上刚刚发布还未出货。但已经出货2年的A100在最新MLPerf中,打破16项性能记录领跑。 可见,仅英伟达这两款高端GPU的断供,直接打击了智能计算以及AI大模型的训练。 截至发稿前,AMD和英伟达都未予置评。 美国再次加大力度!
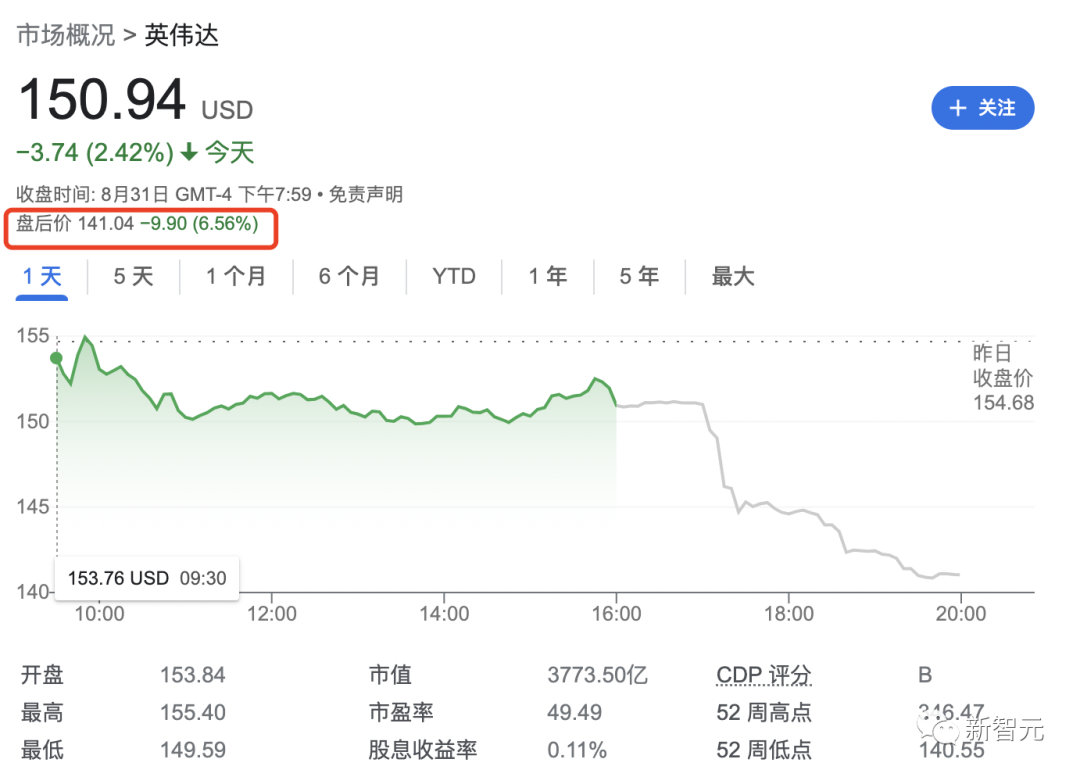
在8月24日英伟达曾预计,第三财季销售额约为59亿美元,然而禁令一出,英伟达第三季度在中国的潜在销售额可能会损失4亿美元,如果客户不想购买替(旧)代(的)产品,而美国政府不及时或拒绝向重要客户发放许可证的话。 此外,据AMD的一位发言人称,美国政府也已经通知他们说要停止向中国出口顶级的人工智能芯片。 AMD表示,新的许可要求将阻止MI250芯片运往中国,但MI100芯片应该不会受到影响。 AMD认为,新规并不会对其业务产生实质性影响。但股价仍在开盘后下跌了。 外交部商务部回应对国内外影响有多大? 近年来,美国不仅针对中国不断地加强芯片的出口限制,并且还试图将制造业带回本土。 拜登已经正式签署《芯片与科学法案》,美国商务部向中国断供了可用于14nm以下先进制程芯片制造的设备,实施了对EDA软件工具的出口管制,且美国正在促成与其他国家的结盟。 相关专家表示,美国此次对英伟达和AMD实施芯片的出口禁令,“对中国芯片产业来讲,尤其是GPU企业和处理器设计企业,是个利好。” “出于性能、功耗等因素,国内高端GPU用户对国产GPU接纳度较低。如果美国断供,将会倒逼他们采用国产GPU,从而加速国产GPU企业进行技术迭代和性能改进,进而推动GPU的国产化进程。” “此外,断供高端 GPU 芯片带来的危机感将传递至我国整个芯片产业,终端应用厂商们将更深刻意识到要尽快摆脱对国外的依赖,尽量使用国内的晶圆代工厂商或国内设备。”他补充到。 或受此影响,今日多只GPU概念股走高。截至午间,寒武纪涨15.25%,盘中一度涨停;海光信息涨15.17%;诸多其他GPU相关企业也跟涨。 “对于NVIDA、AMD来说是利空的,中国毕竟也是他们的一个主要的市场,失去中国这个市场,对他们的营业额等各方面都会造成不少的损失。” 除了阻碍英伟达在中国高达4亿美元的业务以外,还会影响国内AI领域的研究。
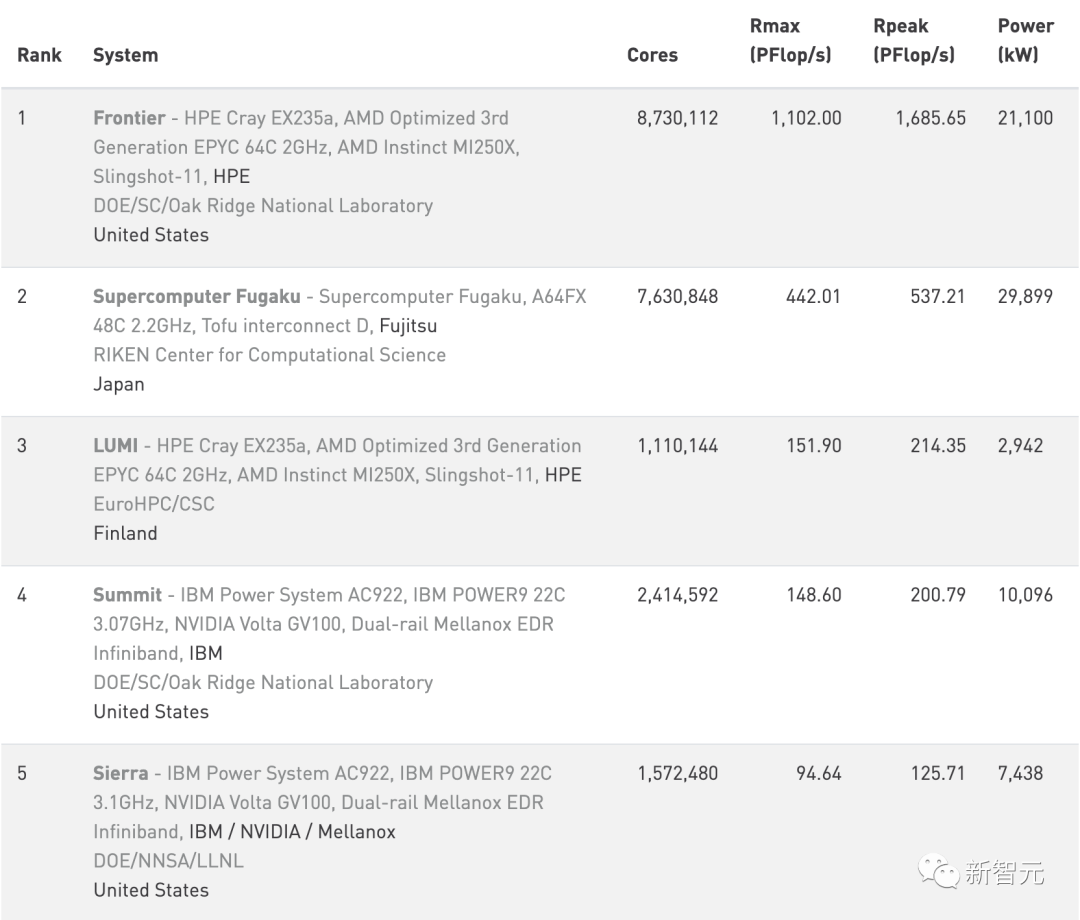
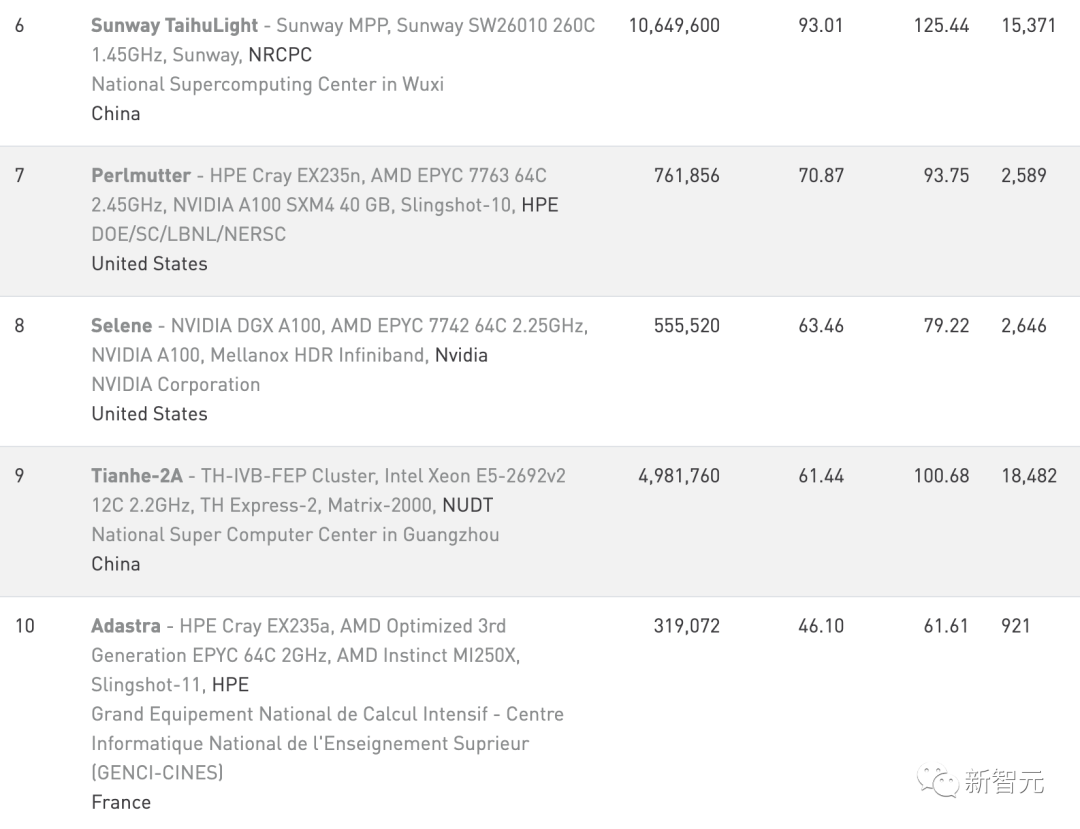
不过目前来看,对消费电子领域的影响并不严重。除了这两家的芯片,还有像高通、联发科、三星等芯片可用。 智能计算 但是,大多数国内服务器离不开这两家都芯片。显然,美国的这番断供就是冲着算力去的,目的就是阻碍中国在人工智能领域领先世界。 建设强大的智算中心就需要高端GPU,如果没有智算,智慧交通、智慧城市、工业互联等众多领域都会受到影响。 因此,芯片断供将会直接影响国内的云计算产业及人工智能产业的发展。 根据6月份最新全球超算TOP500榜单,排在前十的超算中基本上都用到了AMD、英伟达、英特尔的处理器或技术。 其中,中国神威·太湖之光超级计算机用的是我们自主研发的神威26010众核处理器。天河二号超级计算机则是使用基于英特尔集成众核架构的Xeon Phi 31S1P协处理器。 因此,断供AMD和英伟达对我国最有影响力的两大超算并未造成影响。
然而,对于国内提供服务器的企业来讲,就不那么幸运了。服务器都是企业用得多,比如数据中心、云计算。 目前,国内像阿里等公司都在开始自研云原生处理器,这是值得肯定的。 元宇宙 要知道,GPU是元宇宙核心计算资源的底座。未来,元宇宙市场规模或超4700亿美元。 元宇宙中有大量的程序需要计算,构成元宇宙的虚拟内容、区块链网络、人工智能技术都离不开算力的支撑。 没有强大的算力支撑,元宇宙就如同空中楼阁。 因此,元宇宙中更加真实的建模与交互需要更强的算力作为前提,更加说明我们自研GPU的重要性。 AI大模型 另外,如果没有英伟达和AMD等公司的芯片,国内在图像、语音识别以及其他机器学习方面的任务也将受到严重的影响。 2020年大火的GPT-3参数规模达到1750亿,而且,其训练数据集规模也超过500GB。 训练这么大的AI模型,必然会吃很大的算力,仅GPT-3就消耗了10000块GPU,花了30天才完成。 那么,断供高端GPU将如何影响国内AI模型的训练呢? 拿英伟达A100来举例,它的深度学习性能在2021年的实测中可达V100的3.5倍。而在最新的AI芯片跑分大赛结果中,A100打破了16项性能纪录。 相比于只有540亿个晶体管的前辈A100,英伟达在H100中装入了800亿个晶体管,并采用了定制的台积电4nm工艺。 在算力上,H100的FP16、TF32以及FP64的性能都是A100的3倍,分别为2000 TFLOPS、1000 TFLOPS和60 TFLOPS。此外,H100还增加了对FP8的支持,算力高达4000 TFLOPS,比A100快6倍。 在AI训练中,如果采用H100来训练GPT-3的话,就可以将速度提升6.3倍,如果结合新的精度、芯片互联技术和软件,则可以提升至9倍。
国产GPU准备好了吗?
|
Copyright © 2022 信创观察网 版权所有 晋ICP备20006596号-5

晋公网安备 14010502051156号